Hybrid Cloud Experts
Bit Refinery provides hosting infrastructure allowing companies to run their workloads where it makes sense
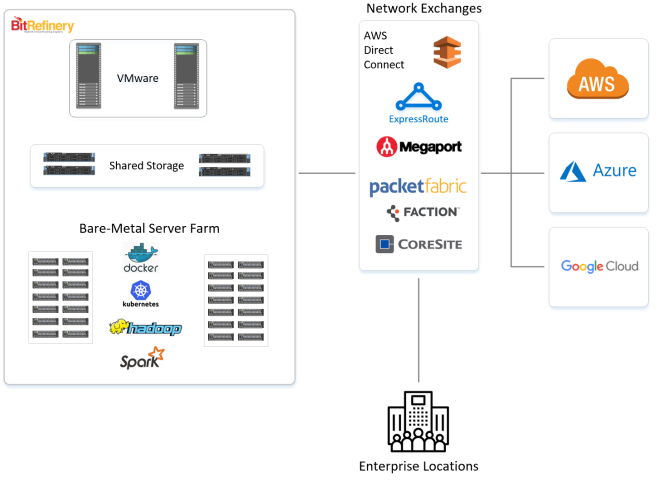
Run your workloads where it makes sense
Hybrid cloud is all about choice. Certain workloads demand performance and cost efficiency that a public cloud such as AWS simply cannot meet. Bit Refinery has been providing private infrastructure for over a decade now. We’ve seen it all from thin to thick clients to Hadoop and now the container hype.
By 2020, 90 Percent of Organizations Will Adopt Hybrid Infrastructure Management
Gartner, 2017Cloud First?
Not Really
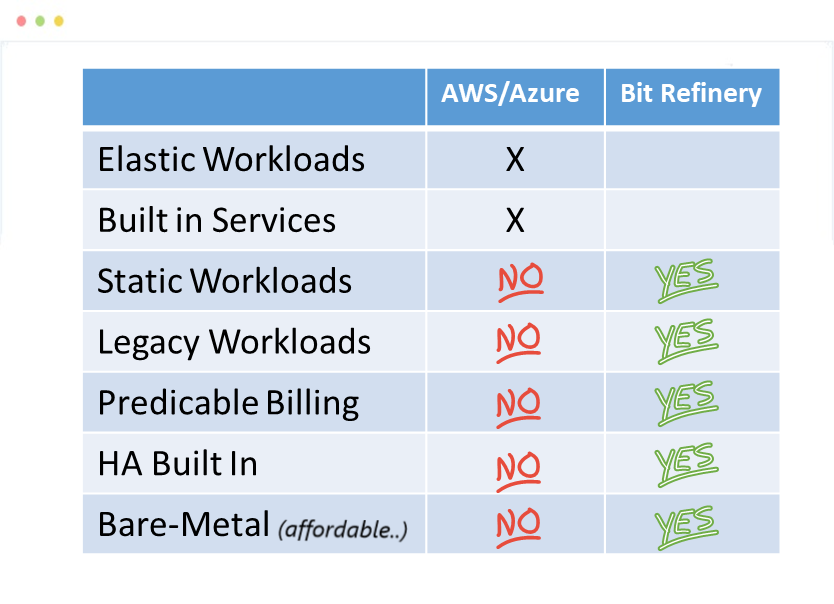
We’ve seen more and more companies adopt a “cloud first” strategy which usually leads them to something we call the “public cloud hangover”. The following table helps illustrate this.
From an Enterprise VMware environment to custom built bare-metal servers, we provide what the public cloud providers do not.
Our Customers = Our Partners

Unlike other infrastructure providers, we consider our customers to also be our partners. You are not a number to use and live by the saying: “if you are successful, then so are we”.
“The magic formula that successful businesses have discovered is to treat customers like guests and employees like people.”
Some of our customers have been with us for over 10 years and continue to trust us with powering their
With over 10 years of experience, let us help you with your journey into the Cloud
Enterprise VMware
Our Enterprise VMware infrastructure is solid enough for a single VM to 1000s.
Bare-Metal Infrastructure
When you just need the raw power of dedicated servers for containers or any other big data requirements.
Low Cost Storage
Shared storage with control knobs for different performance levels to meet any application requirements.
Layer 2 Direct Connect
Enjoy on-ramps to the cloud from your premise,your data center or from cloud to cloud. Leverage up to 100Gbps dedicated links accessible in every major metropolitan market.
Migration Consulting
Let us help you migrate your existing workload and infrastructure to the correct home. Whether it be on AWS or one of our many locations, we’ll assist you with this journey.
Managed Services
We offer a full range of managed services from simple monitoring and administration to full architecture and development, let our experts help your team manage your environment
Unique Bare-Metal Pricing
Our customers are also our partners. Our unique bare-metal server pricing model allows for our customers to benefit from a tiered pricing model. Each of our custom bare-metal servers will be sized according to your needs and after the server is paid off, the price drops so you can reap the benefits of ownership as well.

Some of our many excellent partners



