
High-throughput ETL in 2026 looks very different than it did a few years ago: more streaming and CDC, larger semi-structured payloads, heavier use of columnar formats, and more teams treating “ELT” as a constant, always-on service. Yet one thing hasn’t changed—when your pipelines run hot 24/7, bare metal is still hard to beat.
This isn’t a “cloud bad” argument. Cloud is excellent for experimentation, global distribution, and short-lived spikes. The problem is that high-throughput ETL is usually not spiky. It’s sustained, I/O-heavy, sensitive to tail latency, and frequently dominated by data movement costs.
Below is a practical, engineering-focused breakdown of why bare metal continues to outperform cloud for sustained ETL in 2026, and how to design a hybrid approach that keeps flexibility without paying hyperscale tax.
1) ETL is an I/O problem disguised as a compute problem
When ETL slows down, the first instinct is to add vCPUs. In reality, the bottlenecks are usually:
- Disk throughput and queue depth during large sorts/joins, compaction, and file merges
- Network throughput between sources, staging, and sinks
- Tail latency from noisy neighbors and shared storage
- Memory bandwidth for parsing, hashing, and compression
Public cloud instances can offer strong peak performance, but consistency is where ETL pipelines get hurt. Multi-tenant storage and network layers introduce variance that shows up as:
- longer job makespans (missed SLAs)
- bigger buffer requirements (Kafka retention, staging disk)
- more retries (and more cost)
On bare metal, you control the whole path: PCIe lanes, NVMe devices, RAID layout, IRQ affinity, and NUMA boundaries. That control matters when your “simple” transform is doing tens of GB/s of scan + decompress + shuffle.
2) Predictable performance beats elastic performance for always-on pipelines
Elasticity helps when workload is bursty. Many ETL workloads aren’t.
If you’re continuously ingesting clickstream, ad events, network telemetry, or financial transactions, you’re typically running:
- ingestion + validation
- enrichment joins
- deduplication / late-arriving handling
- incremental merges
- downstream publishing
…every minute, every hour, every day.
In those conditions, “scale to zero” doesn’t apply. You end up paying for capacity all the time—and your main win becomes predictability. Bare metal wins because:
- no CPU steal time from co-tenancy
- consistent disk latency (especially with local NVMe)
- stable network throughput (no hidden throttles)
For frameworks like Spark, Flink, dbt + Trino, or custom Rust/Go pipelines, predictable throughput often reduces total cost more than theoretical peak scaling.
3) Egress and data gravity are still the silent budget killers
In 2026, many teams have accepted that data gravity is real: once you centralize large datasets in one place, moving them repeatedly becomes expensive and slow.
ETL is, by definition, data movement. The cloud pricing model tends to penalize that:
- data pulled from SaaS sources into cloud
- replication across regions/accounts
- exporting curated datasets to customers
- moving data into on-prem or another cloud
Even if your compute is “reasonable,” ETL pipelines often push terabytes per day across boundaries. Hyperscale egress fees turn sustained ETL into a variable, hard-to-predict line item.
Bit Refinery takes a different approach: $0 egress fees with unlimited 1 Gbps bandwidth included, designed for high-transfer workloads where “getting the data out” is part of the job—not a surcharge.
4) Local NVMe + right-sized RAM is a cheat code for transforms
Modern ETL does a lot of:
- parsing JSON/Protobuf/Avro
- dictionary building
- compression/decompression
- sorting and grouping
- spill to disk under pressure
A bare-metal box with large memory and fast NVMe can flatten these bottlenecks.
For example, Bit Refinery’s dedicated server tiers are intentionally sized for data-intensive work:
- Silver: 48 cores, 512 GB RAM, 19.5 TB RAID6 SSD
- Gold: 80 cores, 1 TB RAM, 44 TB RAID6 SSD
- Platinum: 80 cores, 3 TB RAM, 150 TB RAID6 SSD
This class of configuration is ideal for “hot staging” patterns—where you land raw data locally, transform at line-rate, then publish to ClickHouse, Iceberg, Delta, or downstream APIs.
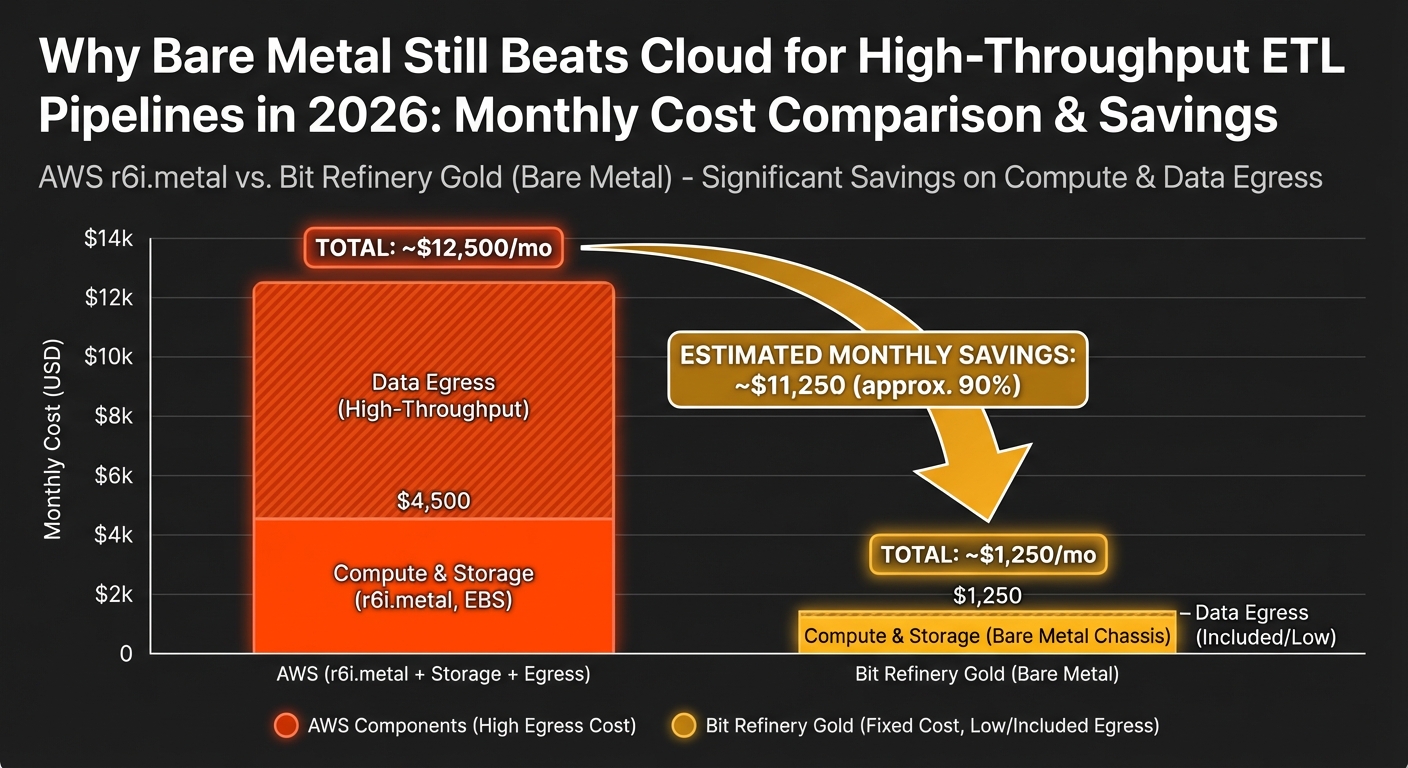
In cloud, you can approximate it, but the cost tends to be much higher. A comparable AWS configuration (r6i.metal + ~40 TB storage) can run about $10,658/month versus Bit Refinery Gold at $2,800/month—and heavy transfer can add $16,200+/month in egress alone.
5) Multi-tenant blast radius is real—especially during peak business hours
ETL reliability isn’t just about speed; it’s about being able to finish when everyone else is also doing work.
In hyperscale environments, you can still run into:
- noisy-neighbor effects on shared storage
- network contention
- maintenance events
- quota limits (API throttles, IP limits, ephemeral storage caps)
You can engineer around many of these issues, but the mitigations (multi-AZ redundancy, overprovisioning, cross-region replication) often erase the perceived simplicity and increase cost.
Bare metal reduces your dependency on shared infrastructure layers. You still architect for failure, but you’re not paying to avoid other tenants’ variance.
6) ETL stacks are converging on “fast lakehouse + fast serving”
A common 2026 pattern is:
- Object storage as the durable landing zone (S3-compatible)
- Open table formats (Iceberg/Delta/Hudi)
- Distributed SQL for transformation and federation (Trino)
- Real-time analytics stores for serving (ClickHouse)
Bare metal is a strong foundation for this architecture because you can run the whole stack with consistent throughput:
- MinIO for S3-compatible object storage (shared or dedicated)
- Trino for high-concurrency SQL transforms across sources
- ClickHouse for low-latency analytics and high-ingest workloads
Bit Refinery supports this directly via managed ClickHouse and MinIO (with Quantrail Data) and Trino consulting/managed services—so teams can focus on pipeline logic, not constant platform firefighting.
7) Hybrid still wins: “Own the base, rent the spike”
The best answer is rarely “all cloud” or “all on-prem.” A durable strategy for ETL in 2026 is:
- Own the baseline on dedicated infrastructure (ingestion, staging, steady-state transforms, serving)
- Burst to cloud for:
- backfills
- one-time reprocessing
- large ad-hoc experiments
- short-lived ML feature generation
This is Bit Refinery’s core philosophy: “Own the base, rent the spike.”
Because Bit Refinery data centers have sub-2ms latency to major public clouds, you can keep your primary data plane on bare metal and still use cloud services when they’re genuinely the right tool.
Practical decision checklist: should this ETL run on bare metal?
Bare metal is usually the right move when you have:
- sustained ingestion (24/7) and predictable baseline demand
- heavy shuffle/spill workloads (joins, sorts, compactions)
- large daily data movement (especially outbound to customers/tools)
- strict latency SLOs or tight batch windows
- high storage density needs (tens to hundreds of TB hot)
Cloud is usually the right move when you have:
- highly bursty workloads with long idle periods
- global edge requirements across many regions
- deep dependence on proprietary managed services you don’t want to replace
A reference architecture that works well on bare metal
If you’re designing (or redesigning) a high-throughput ETL platform, a proven layout is:
- Landing/Buffer: Kafka/Redpanda + local NVMe staging
- Transformation: Trino for SQL-based ELT + Spark/Flink for complex streaming
- Storage: MinIO (S3-compatible) as durable lake storage
- Serving: ClickHouse for real-time analytics and fast dashboarding
- Ops: aggressive observability (OpenTelemetry), backpressure controls, and immutable deployments
This architecture benefits disproportionately from consistent disk and network performance—and is often cheaper to run on dedicated servers than an equivalent always-on cloud footprint.
Where Bit Refinery fits
Bit Refinery is built for exactly this problem space: high-throughput, data-intensive infrastructure with predictable cost.
- Bare metal and virtual servers with fixed monthly pricing
- $0 egress fees (unlimited 1 Gbps included)
- 99.99% uptime SLA in Denver and Seattle (New Jersey coming March 2026)
- Managed and consulting services for ClickHouse, Trino, and MinIO
If you’re running ETL that never sleeps, the fastest path to lower cost and higher reliability is often to move the baseline onto dedicated hardware, then selectively burst to cloud when it’s actually advantageous.
If you want a second set of eyes on cluster sizing, storage layout (NVMe vs RAID6 SSD), ClickHouse/Trino performance, or a migration plan that doesn’t break SLAs, contact us.