
The internet is buzzing about AMD's Ryzen AI Max+ 395 "lunchbox" that can supposedly run a 235B parameter model locally for a fraction of cloud GPU rental costs. The demo is impressive. Unified memory architecture that lets one compact box hold models that previously required server racks? That's real engineering progress.
But here's the part the hype cycle is conveniently skipping: these devices are optimized for one user doing one thing at a time.
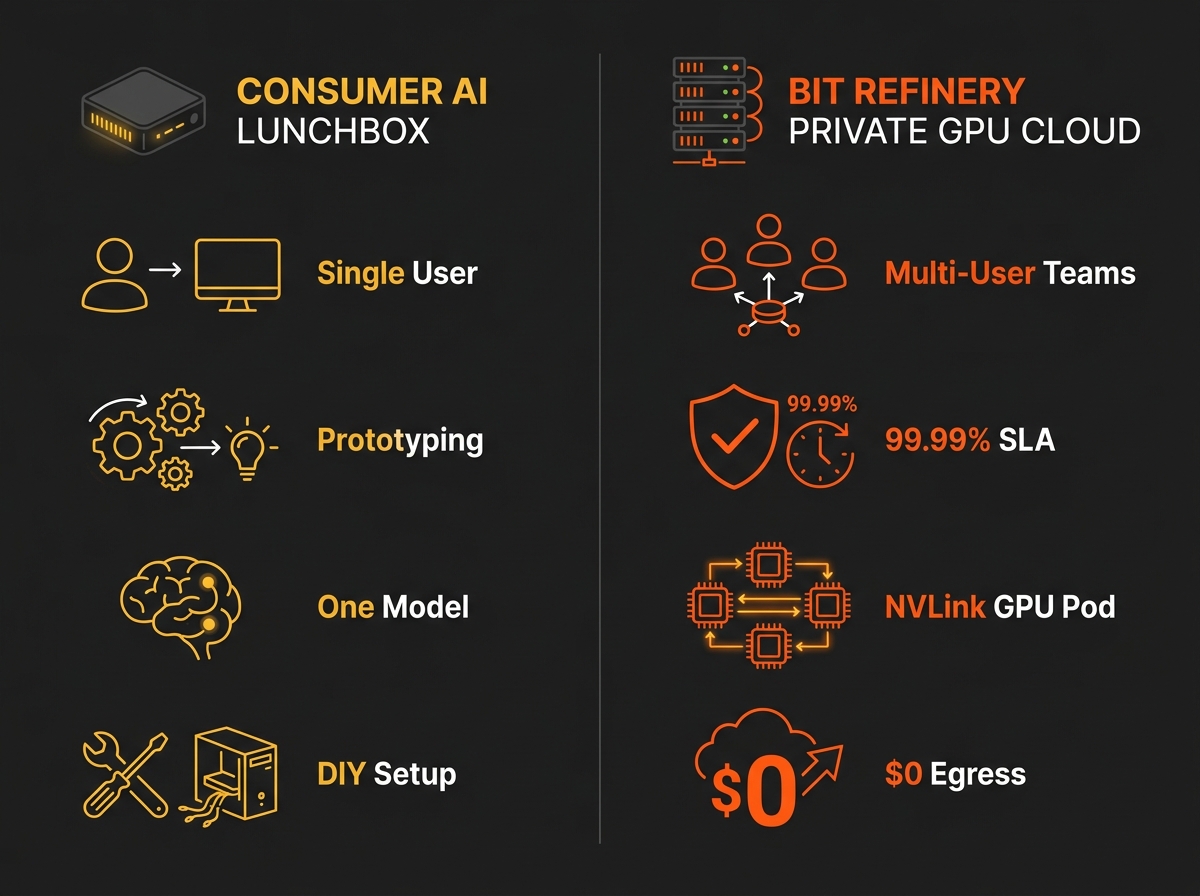
Consumer AI mini PCs and high-end desktop GPUs shine for solo inference. They struggle the moment multiple people, production SLAs, or team-scale workloads show up. At Bit Refinery, we run dedicated GPU infrastructure for companies every day. We see exactly where consumer-grade "AI PCs" stop being sufficient and where professional private GPU hosting becomes the only rational choice.
Single-User Excellence vs. Multi-User Reality
A device like the GMKtec EVO-X2 or similar Ryzen AI Max+ 395 mini PC (or even a high-end RTX 4090/5090 desktop) is excellent at:
- Running one large model for a single developer or power user
- Local RAG over private documents with strong privacy
- Experimentation and prototyping without per-token bills
- Offline or air-gapped workflows
What it is not designed for:
- Multiple people (or agents) hitting inference concurrently
- Production APIs that need consistent latency under variable load
- Team-scale fine-tuning or LoRA training jobs that run for hours or days
- Workloads requiring NVLink-scale multi-GPU peer-to-peer bandwidth
- Anything that must survive a power blip, driver crash, or "I need this running at 3 a.m. with no babysitting"
Desktop and mini-PC form factors are fundamentally single-tenant, single-node designs. They lack the power delivery, sustained thermal headroom, remote management (IPMI/BMC), redundant networking, and professional monitoring that production environments require.
The Hidden Costs of "Just Buy a Few Consumer Cards"
Many teams try the "build it ourselves" route first. They buy a few high-end consumer GPUs, stuff them in a workstation or DIY server, and quickly discover:
- Management tax — You just hired (or became) a part-time GPU sysadmin. Driver updates, power/cooling issues, BIOS quirks, and "why is this job suddenly 4x slower?" debugging all land on someone's plate.
- Concurrency problems — One person's long-context generation or fine-tuning job can starve everyone else on the same box.
- No real isolation — Consumer setups rarely deliver proper multi-tenancy or workload isolation without significant custom engineering.
- Compliance & audit reality — Try explaining to a security reviewer or customer that your model serving runs on a desktop in the engineering closet with consumer-grade remote access.
- Scalability ceiling — Adding the 5th or 6th GPU turns into a networking, power, and cooling project instead of a simple provisioning request.
This is exactly why we built Bit Refinery Private GPU Cloud.
What Professional Dedicated GPU Infrastructure Actually Delivers
Our Private GPU Cloud gives you single-tenant, dedicated NVIDIA GPUs (RTX 6000 Ada 48 GB, RTX PRO 5000 Blackwell, and higher-end datacenter cards on request) in a proper Tier 3 facility with:
- True isolation — Your VM runs on dedicated silicon. No noisy neighbors. No shared GPU memory. Full root + SSH access.
- NVLink-connected pods — Up to 7 GPUs with high-bandwidth peer-to-peer connectivity for serious multi-GPU workloads.
- Predictable economics — Flat monthly pricing (example: RTX 6000 Ada at $790/mo, multi-GPU configs accordingly). 10 TB egress included. $0 overage surprises. No per-second billing.
- Enterprise-grade reliability — 99.99% uptime SLA, redundant power/cooling/networking, 24/7 monitoring.
- Privacy by architecture — We are a GPU hosting company, not an AI lab. Your weights, datasets, and prompts are never ingested or trained on. SOC 2 Type II attested, HIPAA-ready BAAs available.
- Real multi-user capability — Multiple team members or production workloads can run simultaneously without one job destroying performance for everyone else.
You get the control and cost predictability of "owning the base" without the operational burden of running your own hardware.
Here's how the two stack up once real business usage enters the picture:
| Consumer AI Lunchbox / Desktop | Bit Refinery Private GPU Cloud | |
|---|---|---|
| Best for | One user, prototyping, local RAG | Teams, production APIs, sustained training |
| Isolation | Single-tenant box, shared the moment a second user shows up | Dedicated silicon, full root + SSH |
| Concurrency | One heavy job starves the rest | Multiple users & workloads in parallel |
| Multi-GPU | Limited, DIY, no real interconnect | NVLink pods up to 7 GPUs, high-bandwidth P2P |
| Reliability | Desk/closet, power blips, manual restarts | Tier 3, 99.99% SLA, redundant power/cooling, 24/7 monitoring |
| Economics | Upfront hardware + hidden "GPU sysadmin" tax | Flat monthly (e.g. RTX 6000 Ada $790/mo), 10 TB egress, $0 overage |
| Compliance | Hard to attest | SOC 2 Type II, HIPAA-ready BAAs available |
When the Lunchbox Is the Right Tool
We're not anti-consumer hardware. Far from it.
If you're a solo founder, researcher, or developer who wants maximum privacy and minimal ongoing cost for personal or small-scale work — the AMD mini PC (or a well-cooled desktop with a 5090) can be fantastic. Many of our customers use local devices for exactly that and then spin up Bit Refinery pods when they move into production or need to support a team.
The line is simple:
One serious user doing focused work? Consumer hardware can work great.
Multiple people, production SLAs, compliance requirements, or sustained multi-GPU workloads? You need infrastructure built for that reality.
The Bottom Line
The recent AMD demo is exciting because it lowers the barrier for individuals. That's genuinely good for the ecosystem.
But most companies we talk to aren't trying to run one model for one person. They're trying to deliver reliable AI capabilities to teams, customers, or internal tools — with predictable costs, proper isolation, and someone else handling the lights, cooling, and 3 a.m. alerts.
That's the job Bit Refinery Private GPU Cloud was built for.
If you're evaluating options right now — whether you're coming from expensive hyperscaler GPU rentals, a RunPod-style burst environment, or you're hitting the wall with a DIY consumer setup — let's have a direct conversation. We'll show you exactly what a dedicated, NVLink-connected pod looks like for your workload, how fast we can have it SSH-ready, and what the real monthly number is with zero egress surprises.
We've been running serious infrastructure since 2008. We know the difference between "impressive demo" and "this actually runs my business."
Ready to move beyond the lunchbox? Configure your Private GPU Cloud pod, explore bringing your own GPUs (BYOGPU), or get in touch — we're happy to run the numbers and the architecture with you.