
Santiago @svpino called it the "intelligence withdrawal" — the moment AI providers stop eating losses on inference and start charging what it actually costs to run these models. He's right. And it's already happening.
Last week, Anthropic blocked its Claude Pro and Max subscribers from using their flat-rate plans with OpenClaw, the popular open-source AI agent framework. Over 135,000 OpenClaw instances were running on those subscriptions. Overnight, those users went from flat-rate access to pay-as-you-go API billing — and some are reporting cost increases of up to 50x.
This wasn't a bug. It was a business decision. Anthropic's Head of Claude Code said it plainly: "Our subscriptions weren't built for the usage patterns of these third-party tools." Translation: the all-you-can-eat buffet is closed.
Anthropic isn't alone. Google made the same move in February, blocking third-party tools from piggybacking on Gemini CLI's OAuth authentication. The pattern is clear across every major provider — tighten access, enforce terms, push heavy users onto metered billing.
The Subsidy Math Doesn't Work
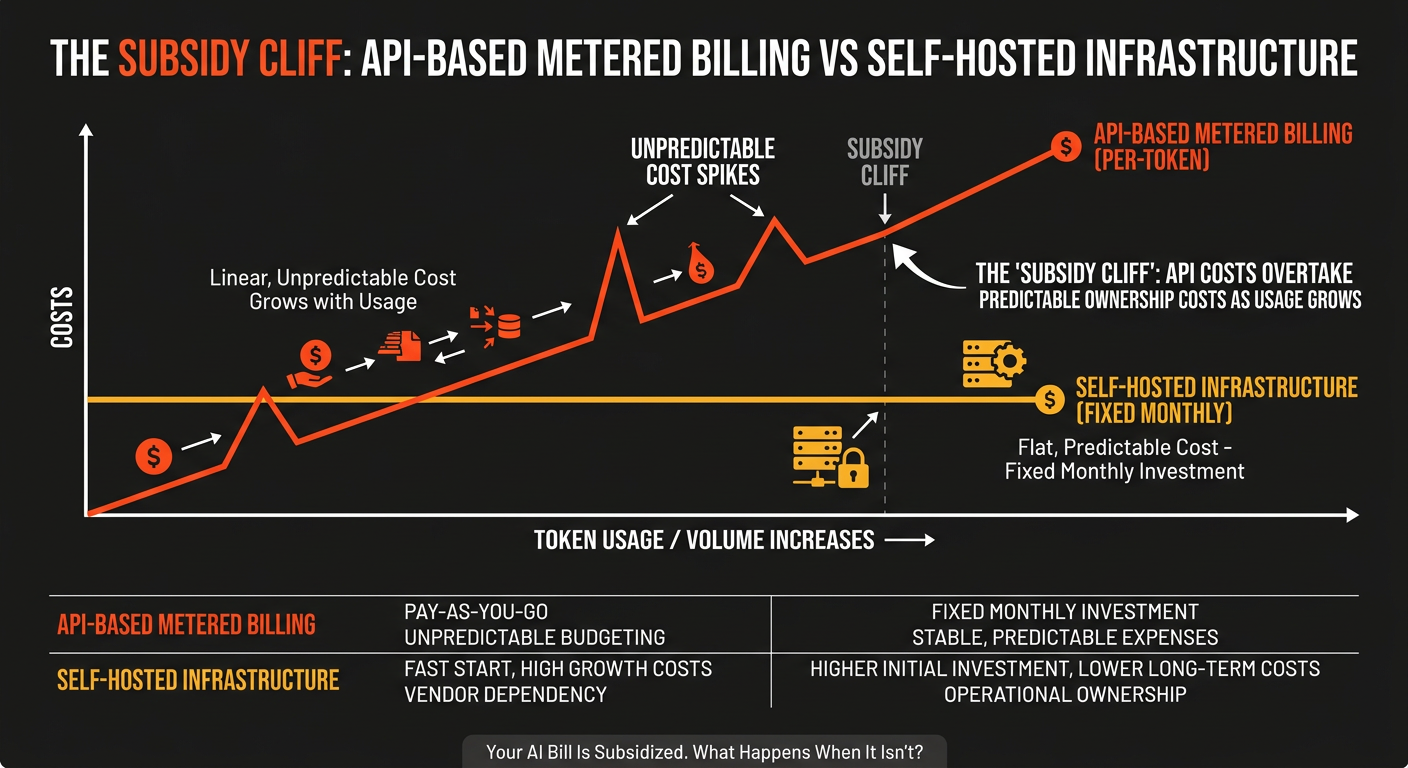
Here's what most teams don't realize: AI inference is expensive to run. When you send a prompt to Claude, GPT, or Gemini, that request hits a GPU cluster that costs millions to build and thousands per hour to operate. The per-token prices you see today are artificially low — subsidized by billions in venture capital and strategic pricing designed to capture market share.
Anthropic has raised over $5 billion. OpenAI has raised over $40 billion. That money funds the gap between what you pay per token and what it actually costs to serve that token. When investor patience runs out — or when these companies need to show profitability — prices go up. Not might go up. Will go up.
The Anthropic-OpenClaw situation is the first visible crack in the AI subsidy cliff. A former employee of multiple frontier AI labs told Axios that Anthropic emphasizes efficiency in how it trains and runs models, while the mindset at OpenAI is that "Altman could always raise more." Both roads lead to the same destination: higher prices for users.
API Routers Don't Fix This
Santiago's recommended solution — a universal API gateway that routes across 500+ providers to find the cheapest token — is clever. But it solves the wrong problem.
If every provider is raising LLM API pricing simultaneously (and they are), routing between them is just arbitrage on a shrinking spread. You're still paying per token. Your costs still scale linearly with usage. Your data still leaves your infrastructure on every request. And you're still one terms-of-service update away from your entire workflow breaking — exactly what happened to 135,000 OpenClaw users last week.
Diversification across API providers isn't resilience. It's the same AI vendor lock-in spread across more vendors.
The Actual Hedge: Own Your Inference
There's a class of AI workloads that doesn't need GPT-5 or Claude Opus. Internal copilots. Document processing. Customer support triage. Code review. Data extraction. These are high-volume, repeatable tasks where a well-configured 7B or 14B parameter model delivers 80–90% of frontier quality — and they account for the majority of tokens most companies generate.
These are the workloads that get destroyed by the subsidy cliff. Not because the task got harder, but because the per-token bill went up 3–5x on a workflow that runs millions of tokens a day.
The alternative is running those models on infrastructure you control. A single GPU-accelerated server running Qwen3-8B or Mistral 7B handles real-time inference at 50–150 tokens per second. The cost? A fixed monthly rate. Not per token. Not per request. Not subject to some provider's capacity management decisions at noon on a Friday.
At Bit Refinery, we deploy open-source models on dedicated GPU-accelerated hardware in our Denver and Seattle data centers. Your data never leaves. Egress is $0 — unlimited. And your bill doesn't change whether you generate 100,000 tokens or 100 million. The self-hosted LLM cost savings on high-volume workloads aren't marginal — they're structural.
Own the Base, Rent the Spike
We're not saying to abandon cloud APIs entirely. Frontier models are genuinely better for complex reasoning, nuanced generation, and tasks where the extra quality matters. Use them for that.
But stop running your entire AI stack through an API that can change pricing, throttle access, or revoke your authentication method with a week's notice. To protect your margins, you must build an AI stack that doesn't break when pricing changes. Move the predictable, high-volume 80% onto infrastructure where the cost is fixed and the access is guaranteed. Use APIs for the remaining 20% where frontier capability actually matters. If you need a hybrid architecture that bridges your private infrastructure and cloud services, that's a solved problem too.
That's the stack that survives the subsidy cliff. Not a smarter router. Not a bigger API credit balance. Infrastructure you control, running models you own, at a price that doesn't change when a provider needs to hit their revenue targets.
The "intelligence withdrawal" Santiago warns about is real. The question is whether you're building on rented ground or on a foundation.
Bit Refinery deploys private LLM hosting on dedicated GPU-accelerated hardware — managed, monitored, and live in 48 hours. Get a custom quote and find out what your inference stack actually costs when you own it.