
The Subsidy Reality
Every time you call the OpenAI API, OpenAI is probably losing money on you. That's not a hot take — it's been reported extensively, and Santiago's viral thread laid it out plainly: Anthropic, OpenAI, and Google are burning billions to keep API pricing below their actual cost of compute. They're buying market share with venture capital, and at some point, those investors want returns.
The canary in the coal mine already sang. Anthropic quietly banned Max plan subscribers from running heavy agentic workloads through tools like OpenClaw — not because the technology broke, but because the economics did. When a company starts rationing access to paying customers, that's not a product decision. That's a margin problem. The subsidies are already unwinding at the edges, and the center won't hold much longer.
What Happens When Prices Normalize
Here's the uncomfortable math: per-token pricing is almost certainly going up 2-5x as these companies stop subsidizing growth and start chasing profitability. OpenAI has already raised prices on older models — GPT-4 Turbo got quietly repriced while everyone was distracted by the new releases. This is the playbook. Cheap until lock-in is complete, then normalize. GCP just doubled egress rates following a similar trajectory, and Twilio did it with SMS. The pattern is not new.
The apps that get hurt worst are the ones built on the assumption that current pricing is permanent. Vibe-coded agents, RAG pipelines, internal copilots — anything generating millions of tokens per day is sitting on a pricing time bomb. A product architected at $0.15/M input tokens does not survive at $0.75/M. That's not a tweak, that's a rebuild.
The API Router Is a Band-Aid
So the smart money is hedging, right? Tools like Kilo Code's gateway or LiteLLM route you to the cheapest available provider in real time. It's genuinely clever engineering. But here's the thing — you're still paying per token, your data is still leaving your network on every single call, and you're playing arbitrage on a market where every provider is raising prices simultaneously.
Routing across 500 providers doesn't change your fundamental position. You're diversified across landlords, not free from rent. You've optimized which API you're dependent on, not whether you're dependent on APIs at all. When the subsidy cliff hits, every provider in that routing table gets more expensive at the same time, because they're all running on the same underlying economics. A smarter router is a better umbrella, not a roof.
The Real Hedge: Own the Base
We've built Bit Refinery around a pretty simple philosophy: own the base, rent the spike. It applies to infrastructure generally, but it maps almost perfectly onto the AI cost problem.
For the 80-90% of your token volume that's routine work — document summarization, customer support triage, internal search, copilot autocomplete, classification — you don't need GPT-4o. You need something fast, private, and cheap. A Qwen3-8B or Mistral 7B running on dedicated hardware handles this workload with genuinely good quality, and your marginal cost per token is effectively zero. It's electricity. That's it.
Save the cloud API calls for the genuinely hard stuff. Complex reasoning, frontier-level coding tasks, multimodal inputs, anything where Claude Opus or GPT-4o actually earns its price tag. Use the frontier models as the spike layer, not the base. When OpenAI raises prices again — and they will — it only affects the 10-20% of your workload that actually needed them.
The Math
Let's make this concrete. Here's what daily token volume costs across different scenarios, using current GPT-4o pricing ($5/M output, $2.50/M input — blended rough estimate of $3.75/M), GPT-4o Mini ($0.15/M blended), and a Bit Refinery private LLM deployment at a fixed monthly rate.
| Daily Token Volume | GPT-4o / mo | GPT-4o Mini / mo | Bit Refinery Private LLM |
|---|---|---|---|
| 500K tokens/day | ~$1,250 | ~$25 | Fixed flat rate |
| 2M tokens/day | ~$4,000 | ~$100 | Same fixed rate |
| 10M tokens/day | ~$25,000 | ~$1,500 | Same fixed rate |
| 50M tokens/day | ~$125,000 | ~$2,500 | Same fixed rate |
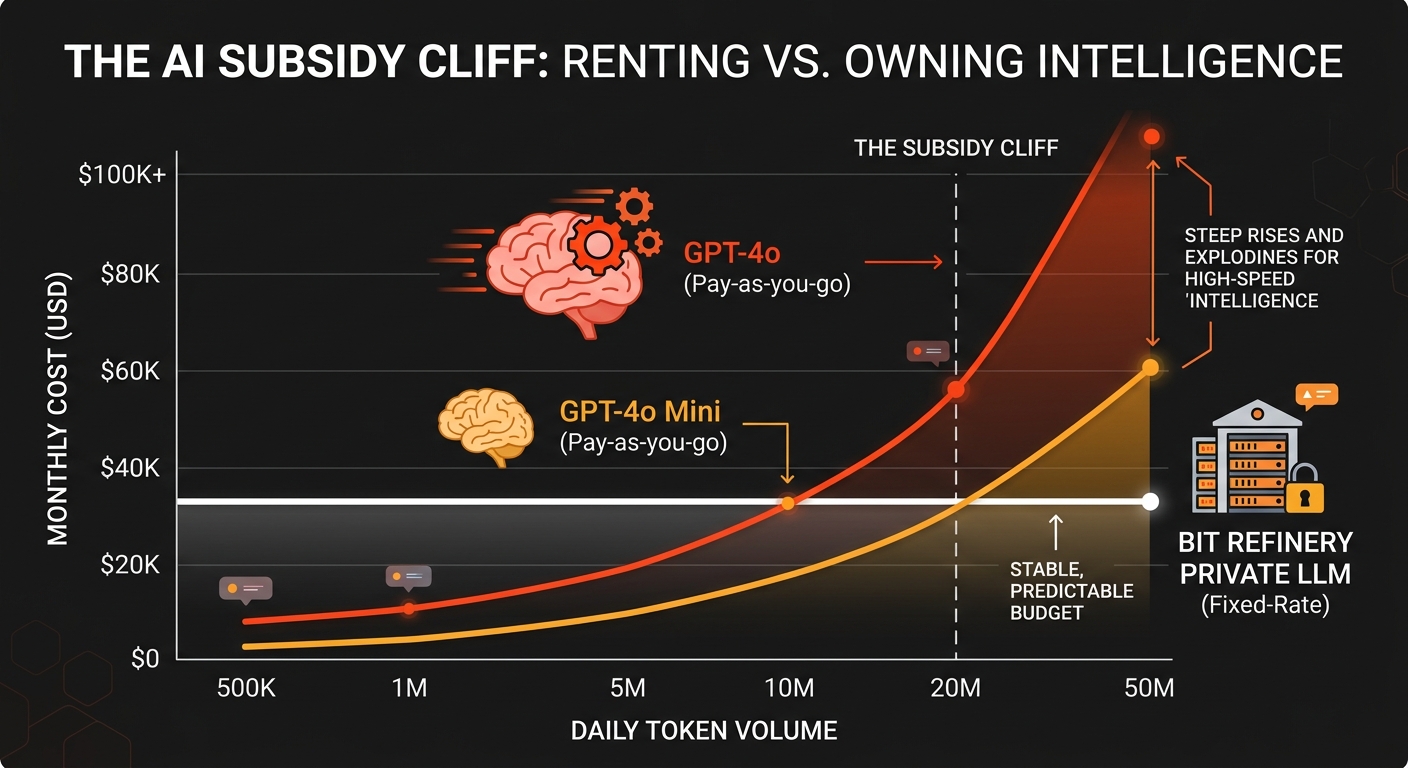
The crossover point depends on your workload, but for most teams running agents or high-volume inference, the fixed-rate model wins somewhere between 2M and 10M tokens per day. And here's the part that matters most: when subsidies end and GPT-4o doubles in price, your Bit Refinery bill doesn't change. Not by a dollar. That's not a feature, that's a structural advantage.
The Stack That Actually Survives
The architecture we'd recommend isn't complicated, but it requires actually committing to it.
Run your base inference workload on dedicated Bit Refinery hardware — one of our Gold or Platinum servers (80 cores, 1-3TB RAM, NVMe storage) with vLLM as your serving layer. vLLM gives you an OpenAI-compatible API endpoint, which means your application code doesn't change. It's a base URL swap. You point your internal tools at your private endpoint for routine calls, and fall through to the OpenAI or Anthropic API for tasks that genuinely need frontier capability.
That's the actual resilience — not routing across providers, but having infrastructure you control sitting underneath the whole thing. If OpenAI goes down, your base workload keeps running, much like how private S3 storage scales without worrying about external service outages. If prices spike, your costs don't. If a compliance requirement lands that says your data can't leave the building, you're already compliant for the majority of your calls.
We're also rolling out Foundry, our management control plane for deploying and monitoring models on bare metal. It handles model versioning, GPU utilization visibility, request logging, and failover configuration — the operational layer that makes running private inference actually manageable at scale rather than a weekend project that never quite works right.
Stop Renting Intelligence
Look, the API economy isn't going away. Frontier models will always exist and there will always be tasks worth paying for. We're not saying throw out your OpenAI key. We're saying stop using it as your only option, because the pricing floor underneath it is temporary and everyone building on it knows it.
The companies that come out of the subsidy cliff in good shape will be the ones that treated AI infrastructure like infrastructure — something you own at the base, not something you rent entirely from a provider whose incentives diverge from yours the moment they hit profitability targets. Relying solely on third-party providers introduces significant account reliability risks that can paralyze your operations without warning.
If you're running more than a few million tokens a day and haven't modeled what your AI bill looks like at 2x current prices, that's the first thing to do. The second thing is to talk to one of our engineers about what a private inference deployment actually looks like for your workload.
Details and pricing for private LLM hosting are at bitrefinery.com/services/private-llm-hosting. We'll size the hardware, recommend the model stack, and show you the crossover math for your specific token volume. No commitment required to have that conversation.